Modelado de la propagación de influenza en redes de contacto mediante un marco SIRS-Miller
Brody Reid —
Actualizado el
Escrito originalmente en abril de 2019. Esta versión ha sido revisada para utilizar un marco SIRS, una distribución binomial negativa de grados y una implementación en Python. El análisis original y sus limitaciones se discuten en la Sección 6.
Resumen: El modelo de Miller se basa en redes de contacto, teoría de probabilidad y dinámica de enfermedades infecciosas para describir cómo se propaga una enfermedad a través de una población. Modelamos la población como una red donde cada persona es un nodo y cada conexión social es una arista. Trabajamos dentro del marco susceptible-infectado-recuperado-susceptible (SIRS), que toma en cuenta el hecho de que la inmunidad a la influenza es temporal, y asumimos una distribución binomial negativa de grados para la red (una elección respaldada por datos empíricos de encuestas de contacto [5]). Ajustamos el modelo al porcentaje ponderado de visitas por enfermedad tipo influenza (ETI) reportado por los CDC durante la temporada 2017–2018, utilizando un modelo de observación con un parámetro de escala y una tasa basal de ETI. El modelo ajustado captura bien la forma general de la curva epidémica, con una tasa de transmisión $\beta \approx 0.47$ por día, un grado medio implícito de $\langle k \rangle \approx 1.49$ y una línea base de ETI de aproximadamente 1%. Discutimos el desempeño del modelo y sus limitaciones restantes.
1. Introducción
Los modelos epidémicos clásicos asumen una población bien mezclada, donde cada individuo tiene la misma probabilidad de encontrarse con cualquier otro. En realidad, las enfermedades se propagan a través de conexiones sociales específicas, y la estructura de esas conexiones determina qué tan rápido y ampliamente puede viajar un brote. En 2011, Joel C. Miller formalizó esta idea en un marco que construye dinámicas de tipo SIR directamente sobre una red de contacto [1], permitiendo que la heterogeneidad en las conexiones sociales de las personas influya en la transmisión.
Aquí, probamos una versión extendida del modelo de Miller contra datos de los Centros para el Control y la Prevención de Enfermedades (CDC) [2]: el porcentaje ponderado de consultas ambulatorias por enfermedad tipo influenza (ETI) reportado a través del sistema de vigilancia ILINet durante la temporada 2017–2018. Dos decisiones clave distinguen este análisis de un modelo SIR-Miller básico. Primero, usamos un marco SIRS: para la influenza, la inmunidad es específica de cada cepa, y una persona que se recupera de una cepa circulante aún puede infectarse con otra, por lo que tratar la recuperación como permanente no es realista. Segundo, modelamos la distribución de contactos usando una distribución binomial negativa en lugar de una Poisson, lo cual refleja mejor la heterogeneidad observada en las redes sociales [5].
2. Redes de contacto
Una red de contacto representa una población como un grafo. Cada persona es un nodo, y cada conexión social a través de la cual podría propagarse una infección es una arista. El número de aristas conectadas a un nodo dado se llama su grado, denotado $k$. Las personas con muchos contactos tienen grado alto; las personas con pocos tienen grado bajo.
La distribución de grados en la población se describe mediante $P(k)$, la probabilidad de que una persona elegida al azar tenga exactamente $k$ contactos. El número promedio de contactos por persona es:
$$\langle k \rangle = \sum_{k=1}^\infty k\, P(k). \tag{2.1}$$Un objeto matemático útil para trabajar con distribuciones de grados es la función generadora de probabilidad:
$$\psi(x) = \sum_{k=0}^\infty P(k)\, x^k. \tag{2.2}$$Esta función codifica toda la distribución de grados en una sola expresión y hace que los cálculos posteriores sean más compactos. Una propiedad útil: el grado promedio es simplemente la derivada de $\psi$ evaluada en $x = 1$, es decir, $\langle k \rangle = \psi'(1)$.
Para ilustrar esto, imaginemos un lugar de trabajo donde la mayoría de los empleados interactúan diariamente con un equipo pequeño, algunos gerentes coordinan entre varios equipos y uno o dos individuos muy conectados parecen conocer a todos. Supongamos que el 60% de las personas tiene 3 contactos regulares, el 30% tiene 8 y el 10% tiene 20. El grado promedio es $\langle k \rangle = 0.6(3) + 0.3(8) + 0.1(20) = 6.2$, pero este promedio oculta una amplia dispersión; el pequeño grupo de individuos muy conectados contribuye desproporcionadamente a la velocidad con la que una infección puede moverse por la red.
3. El modelo SIRS
El modelo SIRS extiende el modelo SIR clásico al agregar una vía de regreso de recuperado a susceptible. La población se divide en tres grupos:
- Susceptibles $S(t)$: personas que podrían contraer la enfermedad.
- Infectados $I(t)$: personas que actualmente la tienen y pueden transmitirla.
- Recuperados $R(t)$: personas que se han recuperado y son temporalmente inmunes.
Los susceptibles se infectan a una tasa $\beta$ por contacto con individuos infectados. Los infectados se recuperan a una tasa $\gamma$. Los recuperados pierden su inmunidad y regresan al grupo de susceptibles a una tasa $\delta$. En una población de $N$ personas, la dinámica es [3]:
$$\dot{S} = -\beta SI + \delta R, \tag{3.1}$$$$\dot{I} = \beta SI - \gamma I,$$$$\dot{R} = \gamma I - \delta R.$$El término $\delta R$ es la adición clave: en lugar de permanecer en el grupo de recuperados permanentemente, los individuos regresan al grupo de susceptibles conforme la inmunidad disminuye. Para la influenza, $\beta \approx 0.06$ por día y $\gamma \approx 0.2$ por día [4]. Para la tasa de pérdida de inmunidad usamos $\delta = 1/365$ por día, lo que refleja aproximadamente un año de inmunidad específica de cepa.
4. El modelo de Miller
El modelo de Miller construye el marco SIR sobre una red de contacto, de modo que la estructura de las conexiones sociales determina cómo se propaga la enfermedad [1]. Aquí lo extendemos para incorporar dinámicas SIRS y una distribución binomial negativa de grados.
4.1 Variables centrales de la red
El modelo rastrea dos probabilidades a nivel de red:
- $\theta(t)$: la probabilidad de que una arista elegida al azar no haya transmitido la infección para el tiempo $t$.
- $\varphi(t)$: la probabilidad de que la persona en un extremo de una arista elegida al azar esté actualmente infectada, pero aún no haya transmitido la infección a través de esa arista.
Podemos pensar en $\theta$ como una medida de cuánto de la red sigue “sin exponer”, y en $\varphi$ como la presión de transmisión activa sobre cualquier conexión dada. Conforme pasa el tiempo, $\theta$ disminuye a medida que ocurre la transmisión, y $\varphi$ evoluciona según qué tan rápido los nodos infectados se recuperan versus qué tan rápido infectan a sus vecinos.
4.2 Distribución binomial negativa de grados
Las encuestas empíricas de contacto muestran consistentemente que el número de contactos sociales por persona presenta sobredispersión: la varianza es mucho mayor que la media, con una cola larga de individuos altamente conectados [5]. Una distribución de Poisson no puede capturar esto, ya que para Poisson la varianza es igual a la media. La distribución binomial negativa agrega un segundo parámetro que controla qué tan dispersa es la distribución, lo que la convierte en una opción mucho más adecuada para los patrones de contacto observados.
La binomial negativa tiene parámetros $n > 0$ (un parámetro de forma que controla la sobredispersión) y $0 < p < 1$ (relacionado con el número medio de contactos). La probabilidad de tener exactamente $k$ contactos es:
$$P(k) = \binom{k+n-1}{k} (1-p)^n p^k, \tag{4.1}$$con media $\langle k \rangle = np/(1-p)$ y varianza $np/(1-p)^2$. Cuando $n$ es grande, la distribución se aproxima a una Poisson; cuando $n$ es pequeño, la cola es pesada y unos pocos individuos muy conectados dominan.
La función generadora de probabilidad es [6]:
$$\psi(x) = \left(\frac{1-p}{1-px}\right)^n. \tag{4.2}$$Sus primera y segunda derivadas, que aparecen en las ecuaciones de Miller, son:
$$\psi'(x) = \frac{np(1-p)^n}{(1-px)^{n+1}},$$$$\psi''(x) = \frac{n(n+1)p^2(1-p)^n}{(1-px)^{n+2}}.$$Evaluando en $x = 1$ se obtiene la media: $\psi'(1) = np/(1-p)$.
4.3 El sistema SIRS-Miller completo
Extender el modelo de Miller a SIRS requiere una variable adicional, $\varphi_R(t)$: la probabilidad de que el nodo base de una arista aleatoria esté actualmente recuperado y la arista no haya transmitido. Bajo la aproximación de que los individuos que vuelven a ser susceptibles reingresan a la red como nuevos (es decir, sus aristas están nuevamente disponibles para transmisión), el sistema es:
$$\dot{\theta} = -\beta\varphi, \tag{4.3}$$$$\dot{\varphi} = -(\beta + \gamma)\varphi + \beta\varphi\cdot\frac{\psi''(\theta)}{\psi'(1)}, \tag{4.4}$$$$\dot{\varphi}_R = \gamma\varphi - \delta\varphi_R, \tag{4.5}$$$$\dot{I} = N\beta\varphi\,\psi'(\theta) - \gamma I, \tag{4.6}$$$$\dot{R} = \gamma I - \delta R. \tag{4.7}$$Sustituyendo las expresiones de la binomial negativa para $\psi'(\theta)$ y $\psi''(\theta)/\psi'(1)$:
$$\psi'(\theta) = \frac{np(1-p)^n}{(1-p\theta)^{n+1}},$$$$\frac{\psi''(\theta)}{\psi'(1)} = \frac{(n+1)p(1-p)^{n+1}}{(1-p\theta)^{n+2}}.$$Las condiciones iniciales son $\theta(0) = 1$, $\varphi(0) = I_0/N$, $\varphi_R(0) = 0$, $I(0) = I_0$, $R(0) = 0$.
4.4 Modelo de observación
El sistema SIRS-Miller produce incidencia absoluta, $N\beta\varphi\,\psi'(\theta)$ nuevas infecciones por día, pero los datos de ILINet de los CDC reportan el porcentaje ponderado de consultas ambulatorias atribuibles a enfermedad tipo influenza (% ETI ponderado). Estas son cantidades fundamentalmente diferentes: la salida del modelo escala con la población total $N$, mientras que los datos de vigilancia son una proporción de las consultas clínicas.
Para salvar esta brecha, expresamos la incidencia del modelo como una fracción de la población,
$$f(t) = \beta\varphi\,\psi'(\theta) = \frac{\beta\varphi\, n p(1-p)^n}{(1-p\theta)^{n+1}}, \tag{4.8}$$e introducimos dos parámetros adicionales. El primero es un parámetro de escala $\rho$, que absorbe la proporcionalidad entre la tasa de infección per cápita real y la fracción de consultas ambulatorias codificadas como ETI. El segundo es una línea base $b$, que representa la tasa de fondo de consultas por ETI causadas por patógenos respiratorios no relacionados con influenza (rinovirus, VSR, etc.) que persiste todo el año. El modelo de observación es entonces:
$$\text{\% ETI ponderado}(t) \approx \rho\, f(t) + b. \tag{4.9}$$Esta formulación evita la necesidad de estimar el número absoluto de infecciones. Los cinco parámetros ajustados son $\beta$, $n$, $p$, $\rho$ y $b$; los parámetros restantes $\gamma$, $\delta$ e $I_0$ se fijan a partir de la literatura.
5. Análisis
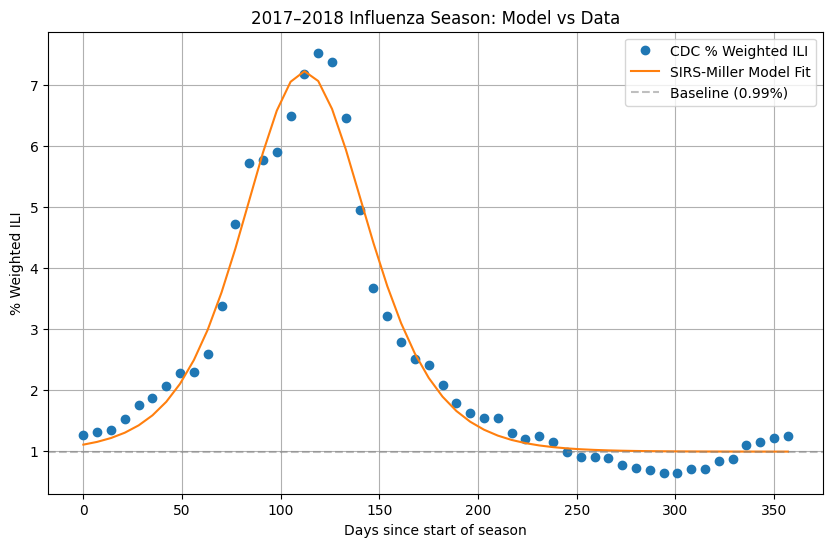
Ajustamos el modelo de observación (4.9) a los datos de ILINet de los CDC para la temporada de influenza 2017–2018 [2], que consiste en 52 observaciones semanales del % ETI ponderado. La temporada abarca desde la semana MMWR 40 de 2017 hasta la semana 39 de 2018. Fijamos $\gamma = 0.2$ por día (período infeccioso promedio de 5 días) y $\delta = 1/365$ por día (un año de inmunidad específica de cepa) con base en la literatura [4]. El conteo inicial de infectados es $I_0 = 12{,}839$, tomado del total de ETI reportado en la primera semana, y $N = 327{,}200{,}000$.
El sistema de EDOs (4.3)–(4.7) se integra numéricamente usando un método Runge–Kutta de cuarto orden (RK45) con tolerancia relativa $10^{-6}$ y tolerancia absoluta $10^{-8}$. El modelo de observación $\rho\,f(t) + b$ se ajusta luego a los datos por mínimos cuadrados no lineales (algoritmo reflectivo de región de confianza), minimizando la suma de residuos al cuadrado entre el % ETI ponderado predicho y el observado en cada semana.
Los parámetros ajustados y sus errores estándar son:
| Parámetro | Estimación | Interpretación |
|---|---|---|
| $\beta$ | 0.47 | Tasa de transmisión por arista por día |
| $n$ | 50.0 | Forma de la binomial negativa (sobredispersión) |
| $p$ | 0.029 | Probabilidad de éxito de la binomial negativa |
| $\rho$ | 41.7 | Escala de tasa de infección a % ETI |
| $b$ | 0.0099 | Tasa basal de ETI (0.99%) |
El grado medio implícito es $\langle k \rangle = np/(1-p) \approx 1.49$, y el valor grande ajustado de $n$ significa que la distribución de grados tiene solo una sobredispersión débil, cercana a una Poisson. La línea base de aproximadamente 1% es consistente con la actividad de ETI fuera de temporada típicamente reportada por ILINet.
El modelo captura bien la forma general de la curva epidémica de 2017–2018: el aumento gradual de octubre a diciembre, el pico pronunciado a finales de enero / principios de febrero, y el regreso a la línea base para finales de primavera. La curva ajustada subestima ligeramente el pico (el modelo alcanza aproximadamente 7.1% versus el pico observado de 7.5%), y los datos observados muestran un hombro secundario alrededor de los días 140–170 que el modelo de una sola cepa no puede reproducir. Esto probablemente refleja la circulación secuencial de influenza A (H3N2) seguida de influenza B durante esa temporada.
6. Discusión
El modelo se ajusta bien a los datos de ILINet de 2017–2018, capturando el aumento desde octubre, el pico pronunciado a finales de enero / principios de febrero, y el regreso a la línea base para finales de primavera. La tasa de transmisión ajustada de $\beta \approx 0.47$ por día es mayor que la estimación de la literatura de $\approx 0.06$ para una población bien mezclada [4], lo cual es esperado: en el modelo de red, la transmisión ocurre a lo largo de aristas en lugar de uniformemente, y el grado medio implícito relativamente bajo ($\langle k \rangle \approx 1.49$) significa que se necesita una tasa por arista más alta para producir la misma dinámica a nivel poblacional. La línea base de $b \approx 1\%$ coincide con la tasa de ETI fuera de temporada típicamente reportada por ILINet, lo que da confianza en que el modelo de observación (4.9) está particionando correctamente la actividad de ETI impulsada por influenza y la actividad de fondo.
Las dos principales decisiones de modelado — cambiar a SIRS y adoptar una distribución binomial negativa de grados — abordan las que se identificaron como las deficiencias más significativas de un enfoque SIR-Miller básico.
La binomial negativa es una elección bien motivada. Mossong et al. [5], en una gran encuesta de contacto que abarcó ocho países europeos, encontraron que la distribución del número diario de contactos presenta una sobredispersión sustancial, con una cola derecha larga impulsada por un pequeño número de individuos muy sociables. Una distribución de Poisson, donde la varianza es igual a la media, no puede representar esto; la binomial negativa sí puede. Sin embargo, en la práctica, el valor ajustado de $n \approx 50$ sugiere que los datos no restringen fuertemente la sobredispersión para esta temporada en particular: con $n$ tan grande, la binomial negativa es casi una Poisson.
La extensión SIRS está igualmente bien motivada para la influenza. Debido a que múltiples cepas co-circulan y la cepa dominante cambia cada temporada, la inmunidad específica de cepa disminuye en una escala temporal de aproximadamente un año. El parámetro $\delta$ captura esto, y su inclusión significa que el modelo puede, en principio, ajustarse a datos de múltiples temporadas en lugar de una sola curva de brote.
Ajustar al porcentaje ponderado de ETI en lugar de conteos brutos de casos evita la necesidad de estimar el número absoluto de infecciones, que es inobservable. El modelo de observación (4.9) introduce solo dos parámetros extra ($\rho$ y $b$), ambos bien restringidos: la línea base $b \approx 1\%$ coincide con la tasa de ETI fuera de temporada típicamente reportada por ILINet, y $\rho$ absorbe la proporcionalidad desconocida entre la tasa real de infección y la fracción de consultas ambulatorias codificadas como ETI.
Una limitación que permanece es la aproximación en la Sección 4.3: los individuos que vuelven a ser susceptibles se tratan como si reingresaran a la red como nuevos. En realidad, si una arista previamente utilizada puede transmitir nuevamente depende del historial inmunológico específico de ambos nodos. Un tratamiento más riguroso rastrearía los estados de las aristas explícitamente, pero esto se vuelve computacionalmente costoso para redes grandes. Como corrección de primer orden, la aproximación es razonable, pero vale la pena tenerla en cuenta al interpretar los valores de los parámetros ajustados.
Los errores estándar de $n$ y $p$ individualmente son grandes, reflejando una fuerte correlación entre ellos: muchas combinaciones de $n$ y $p$ producen grados medios similares $\langle k \rangle = np/(1-p)$. Métodos de verosimilitud perfilada o bayesianos caracterizarían mejor esta incertidumbre conjunta.
Una mejora adicional sería ajustar a datos de incidencia promediados de múltiples años en lugar de una sola temporada, lo que reduciría el ruido año a año y daría una señal más estable para el ajuste. Una extensión multi-cepa que rastree influenza A y B por separado también podría capturar el hombro secundario visible en los datos de 2017–2018.
Referencias
[1] Miller, J. C. (2011). A note on a paper by Erik Volz: SIR dynamics in random networks. Journal of Mathematical Biology, 62(3), 349–358, arxiv.org.
[2] Centers for Disease Control and Prevention. Weekly U.S. Influenza Surveillance Report. cdc.gov. Consultado el 2026-03-12, selección de temporada: 2017–2018.
[3] Weisstein, E. W. Kermack-McKendrick Model. De MathWorld – A Wolfram Web Resource. mathworld.wolfram.com.
[4] Ma, J., van den Driessche, P., & Willeboordse, F. H. (2013). The importance of contact network topology for the success of vaccination strategies. Journal of Theoretical Biology, 325, 12–21.
[5] Mossong, J., Hens, N., Jit, M., Beutels, P., Auranen, K., Mikolajczyk, R., et al. (2008). Social contacts and mixing patterns relevant to the spread of infectious diseases. PLOS Medicine, 5(3), e74.
[6] Proof Wiki. Probability Generating Function of Negative Binomial Distribution. proofwiki.org. Mayo 2013.
[7] Edwards, R. (5 de abril de 2019). Conversación personal.
[8] Ma, J. (1 de abril de 2019). Conversación personal.